

So ultimately I have been working on an unofficial version of the ScyllaDB driver for the Node.JS environment. For those who are not aware, ScyllaDB is a highly performant, low-latency NoSQL database compatible with Apache Cassandra. It offers features like Shard Awareness and superior scalability. For more information on how awesome it is, you can check out this Discord blog post.
Wait, Daniel, even their tutorials include a Javascript driver guide, why would you be working on another one?
Well, you may be right, but actually the driver in these guides is related to the Cassandra one. It works with Scylla easily as it’s compatible, thankfully. The problem is that, of course, Scylla-specific features won’t be available, such as Shard Awareness.
All things considered, the development of the ScyllaDB driver is going pretty well, wrapping the Rust driver through a native module integration. If you are not aware of how this stuff works, I have an in-depth series on native modules.
And to test its capabilities, I decided to implement a project using it. Thankfully, Scylla already has a showcase project, which is also written in multiple other drivers, which is good from a comparison standpoint. The project is care-pet, a step-by-step guide to building an IoT project connected to Scylla Cloud.
But even though the driver itself provides a lot of flexibility and power, it’s usually pretty cumbersome to work directly with the barebones driver. Hence why so many ORMs exist. So I thought to myself, why not create an ORM for ScyllaDB in the Node.JS environment too? We already have the awesome charydbis with the Rust gang.
Bro, but why would you come up with an ORM only for ScyllaDB? Why don’t you extend something like TypeORM or even Prisma?
TLDR: Sowwy, skill issue. 😔
The thing is that it’s not trivial to extend those guys, even more considering the particular constraints of Scylla as it’s a NoSQL wide-column database.
Yeah, but Prisma supports MongoDB which is also NoSQL! 😠
I’m aware, but creating a new engine for Prisma is not that easy. It took them a lot of effort, and as a matter of fact, there is already a feature request for ScyllaDB support from 4 years ago on which a lot of these details are discussed.
So the shorter path is to straight up just get my decorators going on and try something, as I’ve already experienced reflection in TS before. It can’t be that hard, right?
It shouldn’t take a detective to know that these are the famous last words of those who went down a rabbit hole.
Decorating the entities
Okay, so roughly the API I want to achieve here is something along the lines of the following:
import { Uuid } from "@lambda-group/scylladb";
@Entity("users")
class User extends BaseEntity {
@Column({ partitionKey: true })
id: Uuid;
@Column()
name: string;
@Column()
email: string;
}Not too shabby, am I right? Now let’s get to the steps needed to achieve something like this. I will be omitting some code, so if you happen to be curious you can just check the repo.
The @Entity()
Okay, so the job of this decorator is mainly to store the name of the table to be generated as of now.
export function Entity(tableName?: string) {
return (entity: Function) => {
entity.prototype.tableName = tableName ?? snakeCaseTransform(entity.name);
};
}Here, the parameter is optional because we may just infer the table name from the class name itself. We quickly transform the string into snake_case because JavaScript classes are usually in PascalCase, which doesn’t align with most database patterns.
We are even considering adding something like a transform to plural and other modifications, which would require a library because of irregular forms. If you have an opinion on this, please leave a comment on this post.
The Column
Now the hard work begins, as we need to collect and store a lot of data about the attribute.
Wait, that was it for the Entity decorator?
Well, mostly yes. Keep in mind we don’t even have the migration step in a CLI or anything like this. This is more of a POC than a full-blown project.
At least when this post goes to air.
Continuing with the column, we will get something like this:
export function Column(options?: ColumnOptions | string) {
return (target: BaseEntity, key: string) => {
const constructor_ = target.constructor as BaseEntityConstructor;
if (!constructor_.columns) constructor_.columns = [];
const propType = Reflect.getMetadata("design:type", target, key);
const propColumnType = getColumnType(propType.name);
let columnName = snakeCaseTransform(key);
let columnType = propColumnType;
let isPartitionKey = false;
let isClusteringKey = false;
let clusteringKeySequence = 0;
if (typeof options === "string") columnName = options;
else if (typeof options === "object") {
columnName = options.name || key;
columnType = options.type || propColumnType;
if (options.partitionKey) isPartitionKey = options.partitionKey;
if (options.clusteringKey) {
isClusteringKey = options.clusteringKey;
clusteringKeySequence = options.clusteringKeySequence || 0;
}
}
constructor_.columns.push({
key,
columnName,
columnType,
...(isPartitionKey && { partitionKey: true }),
...(isClusteringKey && { clusteringKey: true }),
...(isClusteringKey && { clusteringKeySequence }),
});
};
}Don’t mind the efficiency of this code, it hasn’t even seen the light of refactoring yet. Here it mainly tries to collect data about the attribute’s type automatically through the [G]old import "reflect-metadata" with Reflect.getMetadata("design:type", target, key) and then coerces it to the types we support:
const getColumnType = (type?: string): ColumnType => {
const lowerType = type?.toLowerCase();
switch (lowerType) {
case "string":
return ColumnType.TEXT;
case "number":
return ColumnType.FLOAT;
case "date":
return ColumnType.DATE;
case "uuid":
return ColumnType.UUID;
default:
return ColumnType.TEXT;
}
};and then stores the information in the class’s columns field.
Repository
Okay, now how do we interact with this entity? The idea is to have a repository that implement base methods for the class, so I can use like this:
import { Uuid } from "@lambda-group/scylladb";
@Entity("users")
class User extends BaseEntity {
@Column({ partitionKey: true })
id: Uuid;
@Column()
name: string;
@Column()
email: string;
}
using scyllaDataSource = await new DataSource({ nodes: ["localhost:9042"], }).initialize("example");
const userRepository = scyllaDataSource.getRepository(User);
const user = new User();
user.id = Uuid.randomV4();
user.name = "John Doe";Save
To be able to save this entity shouldn’t be that hard having the informations we already have:
export class Repository<T> {
private dataSource: DataSource;
private tableName: string;
private columns: ColumnDefinition[];
private entityClass: BaseEntityConstructor;
constructor(dataSource: DataSource, entityClass: BaseEntityConstructor) {
this.dataSource = dataSource;
this.tableName = entityClass.prototype.tableName;
this.columns = entityClass.columns ?? [];
this.entityClass = entityClass;
}
async save(entity: T): Promise<void> {
const session = this.dataSource.getSession();
const columnNames = this.columns.map((col) => col.columnName).join(", ");
const values = this.columns.map((col) => entity[col.key]);
const placeholders = this.columns.map(() => "?").join(", ");
const query = `INSERT INTO ${this.tableName} (${columnNames}) VALUES (${placeholders})`;
await session.execute(query, values);
}
}So now we can straight up do the following:
const user = new User();
user.id = Uuid.randomV4();
user.name = "John Doe";
await userRepository.save(user);Okay cool, this must be familiar to many readers as it’s very common syntax in ORMs. What about when we want to select a field then?
Find
export class Repository<T> {
// ...
async findByPartitionKey<U extends string | number | Uuid>(
id: U
): Promise<T[]> {
const session = this.dataSource.getSession();
const columnNames = this.columns.map((col) => col.columnName).join(", ");
const partitionKey = this.columns.find((col) => col.partitionKey);
if (!partitionKey) {
throw new Error("Primary key not found");
}
const query = `SELECT ${columnNames} FROM ${this.tableName} WHERE ${partitionKey.columnName} = ?`;
return (await session.execute(query, [id])).map((row: unknown) => {
const entity = new this.entityClass();
for (const col of this.columns) {
entity[col.key] = this.columnToValue(col, row);
}
return entity;
});
}
}I think I got it, we are in a good track using this pattern
Well, yeah, except that queries can be a little bit more complex considering clustering keys and composite partition keys, there are a bunch of rules, for instance having three clustering keys the order of their definitions matters, so when querying by the third clustering key we NEED to specify the previous two and always the partition key.
Hey, but we have the power of the decorators in our side, why don’t you just do this you silly?
import { Uuid } from "@lambda-group/scylladb";
@Entity("users")
class User extends BaseEntity {
@Column({ partitionKey: true })
id: Uuid;
@Column({ clusteringKey: 1 })
name: string;
@Column({ clusteringKey: 2 })
email: string;
}And then figure out the type from there, achieving something like:
type FindQuery<User> =
| { id: Uuid }
| { id: Uuid; name: string }
| { id: Uuid; name: string; email: string };Which guarantee the order of clustering key and the presence of the partition key. Thank me later 😘.
Oh, dear reader, I wished so hard for this, the problem is that decorators cannot augment types up until TS 5.0.
Don’t you worry kitten, I’ve got a couple of plans, let’s get to them.
Infering the Type System
Wandering the interwebs searching for a solution I stumbled upon mikrorm solution for composite keys
@Entity()
export class Car {
@PrimaryKey()
name: string;
@PrimaryKey()
year: number;
// this is needed for proper type checks in `FilterQuery`
[PrimaryKeyProp]?: ["name", "year"];
constructor(name: string, year: number) {
this.name = name;
this.year = year;
}
}Wait wait wait, so we can try to figure the type of composite keys through this syntax that stores the info in a Symbol instead of the decorators. I got working from their types onwards to the rules we need to fulfill.
Step 1
The first step is to be able to extract from the entity the fields annotated with PrimaryKeyProp.
@Entity("users")
class User extends BaseEntity {
@Column({ partitionKey: true })
id: Uuid;
@Column()
name: string;
@Column()
email: string;
[PrimaryKeyProp]?: [["id"], ["name", "email"]];
}
type Step1 = PrimaryKeys<User>; // [["id"], ["name", "email"]]Okay, so first we need to find a type that has this attribute PrimaryKeyProp.
export type PrimaryKeys<T> = T extends { [PrimaryKeyProp]?: any }
? any
: unknown;Here if we find this PrimaryKeyProp with anything we will return any otherwise unknown. The problem is that we don’t know the type of this damn property. Thankfully we can infer it.
export type PrimaryKeys<T> = T extends { [PrimaryKeyProp]?: infer PK }
? PK
: unknown;There we go, we already have collected the keys. Now we want to merge them into a single array so we can iterate on it easily next.
Step 2
Now the plan is to obtain the type ["id", "name", "email"]. It must preserve the order as for the clustering keys it is very important.
To achieve this we simply create a Flatten type that will recursivelly reduce the dimension of the list.
type Flatten<T> = T extends [infer F, ...infer R]
? [...(F extends any[] ? F : [F]), ...Flatten<R>]
: [];
type Step2 = Flatten<Step1>; // ["id", "name", "email"]The Flatten<T> type recursively deconstructs an array T by checking each element: if the element is an array, it spreads its contents; if not, it treats it as a single-element array, then combines these elements into a single-level array until the entire structure is flattened.
Step 3
Now we need to create the result type which is from the original type get the valid queries, in this case type _ = { id: Uuid; } | { id: Uuid; name: string; } | { id: Uuid; name: string; address: string }.
type Step3 = Something<User>;
// | { id: Uuid; }
// | { id: Uuid; name: string; }
// | { id: Uuid; name: string; address: string }To that we, in the most trivial way (🤓👆), do the following:
export type UnionCombinations<
T,
Keys extends Array<keyof T>,
AccumulatedKeys extends Array<keyof T> = []
> = Keys extends [infer First, ...infer Rest]
? First extends keyof T
? Rest extends Array<keyof T>
?
| StrictPick<T, First | AccumulatedKeys[number]>
| UnionCombinations<T, Rest, [First, ...AccumulatedKeys]>
: never
: never
: never;
export type StrictPick<T, K extends keyof T> = Pick<T, K> & {
[P in keyof T as P extends K ? never : P]?: never;
};Here type UnionCombinations recursively forms combinations of object properties by picking the current key, accumulating it, and combining it with the results of further recursive calls on the remaining keys. While type StrictPick picks specified keys from an object and creates a type where these keys are required while all other keys are explicitly set to never, ensuring they cannot exist in the resulting type.
Step 4
Now we just need to wrap the steps in a single easy to use type, we’re gonna call this one type FilterQuery.
Ayo bro, wait wait. The last one was still too much to me to digest, I mean, look at that type UnionCombinations monstrosity dude, do you expect me to simply get it?
Well, to be fair I haven’t designed this type either, I’ve got some help (🤖), but once it’s done and you know what is trying to achieve is not that hard to grasp, I will leave this one to you as exercise to understand fully that type 😉.
Now to the wrapper:
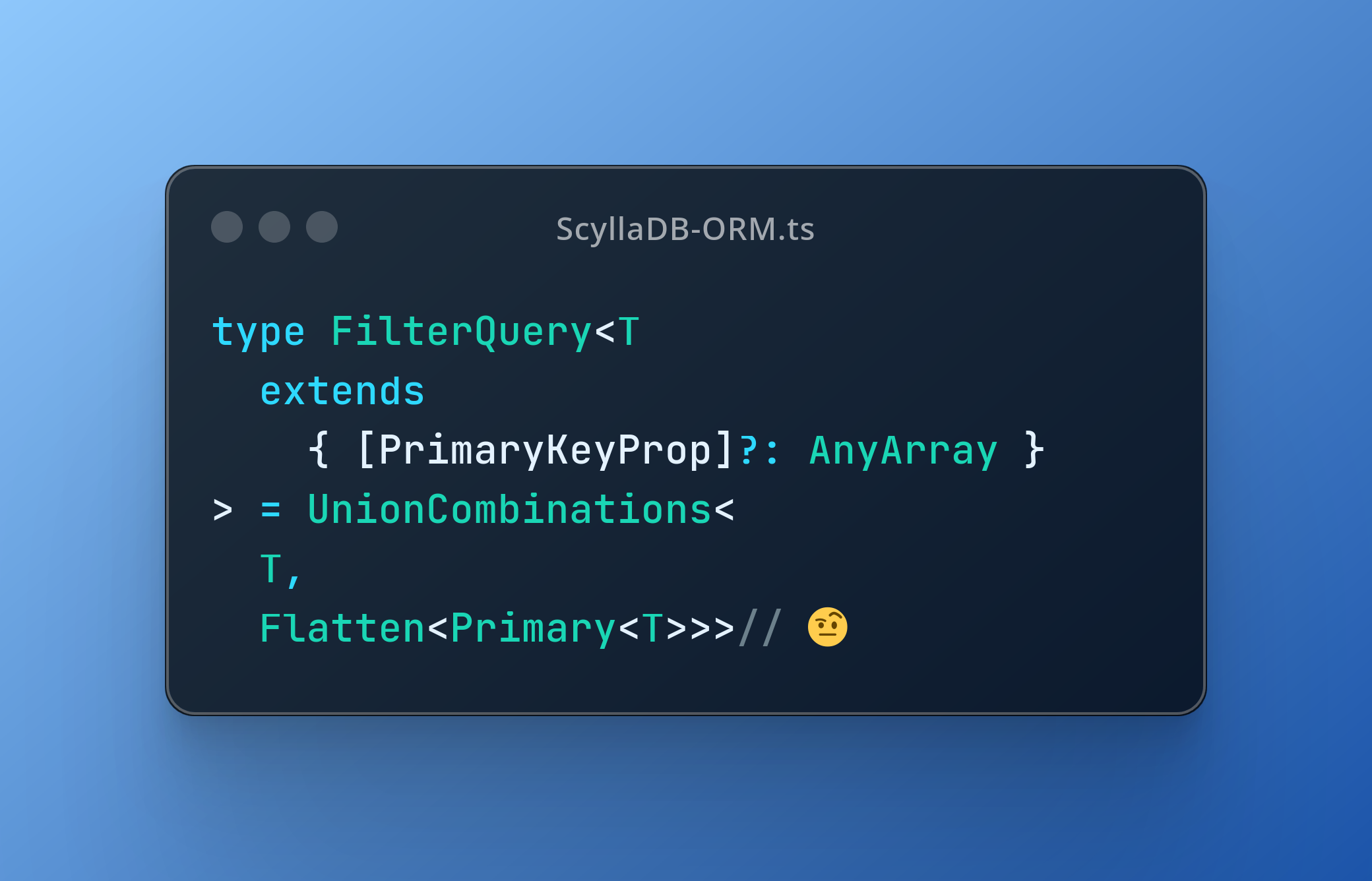
export type FilterQuery<T> = UnionCombinations<T, Flatten<Primary<T>>>;The only problem here is some constraints needed to this to work, is that T must be have the [PrimaryKeyProp], so we need to guard that.
export type FilterQuery<T extends { [PrimaryKeyProp]?: AnyArray }> =
UnionCombinations<T, Flatten<Primary<T>>>;Now we have the type strictness needed to not have to define a async findBy(query: any) anymore and be able to define based on all this hassle we went through.
export class Repository<T extends { [PrimaryKeyProp]?: AnyArray }> {
// ...
async findBy(query: FilterQuery<T>) {
// ...
}
}The end
So I guess our type journey ends here 🥹. It was good while it lasted, I’ve got to say man even though the last year has been tough for me you stood by side at all times and …
Yo yo yo, chill. You don’t have to worry bro, we got so many things to explore yet. Scylla got some cool stuff we need to deal with still, for instance filtering on which we can query by fields that are not in the PrimaryKey, and we will have to deal with this in a way that it’s clear to the user that they are deciding to use it, perhaps through a { withFiltering: true } field in the query that will unlock the ability to do so.
…
Okay, not only that I still have some other paths I want to explore, such as env.d.ts allowing to generate much powerful types. Astro generates this in their CLI, so we’ve got some things up or sleeves to try.
So yall, stay tuned for the next steps of this journey, leave a comment, consider contributing to the repo and have a nice one. See ya 👋